Generierung künstlicher Bild- und Videodaten für medizinische Deep-Learning-Anwendungen
- Ansprechperson:
- Projektgruppe:
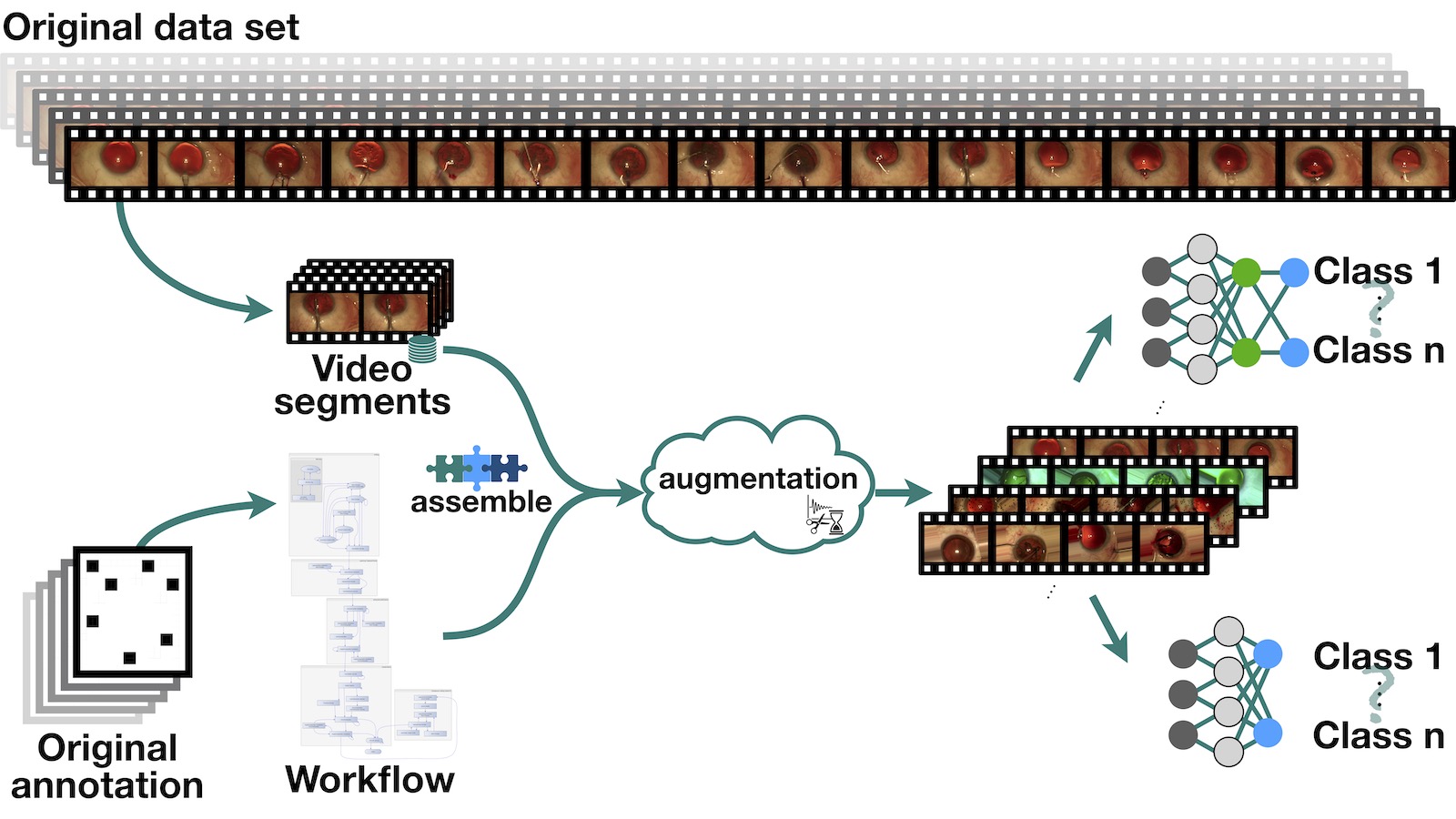
Neuronale Netze haben in den letzten Jahren bemerkenswerte Ergebnisse bei der Ereigniserkennung im Bereich der medizinischen Bild- und Videoanalyse erzielt. Eine der größten Einschränkungen für die Anwendung von maschinellem Lernen ist der Mangel an verfügbaren annotierten Trainingsdaten. Dieser Mangel bezieht sich nicht nur auf die Anzahl der verfügbaren Datensätze, sondern auch auf die Anzahl der Variationen von Bildern und Videos in den vorhandenen Datensätzen. Besonders im medizinischen Bereich ist es schwierig, die Anzahl der Datensätze zu erweitern. Die Gründe dafür sind vielfältig. So können beispielsweise rechtliche Belange die Veröffentlichung der Daten verhindern, oder das Auftreten einer Krankheit ist sehr selten und kann deswegen nur schwer erfasst werden. Außerdem müssen medizinische Daten von Experten in einem teuren und zeitaufwändigen Prozess annotierte werden. Bestehende Methoden zur Datenanreicherung werden häufig auf den Bildbereich angewandt. Mit diesen Methoden lassen sich aber keine ausreichend unabhängige Trainingsdaten von Videodatensätzen im Bereich der Videoanalyse mit maschinellem Lernen erstellen.
Daher ist es notwendig, neue Methoden zu entwickeln, um den Datensatz retrospektiv zu erweitern oder synthetisch neue Datensätze mit Annotationen zu erzeugen.
In meiner Forschung beschäftige ich mich mit der Entwicklung von neuen Methoden, aber auch der Untersuchung, wie man die vorhandene Methode für die Erweiterung von Video- und Bilddatensätze kombinieren muss um die Erkennungsleistung z.B. von neuronal Netzwerken zu verbessern.