Generation of Artificial Image and Video Data for Medical Deep Learning Applications
- contact:
- project group:
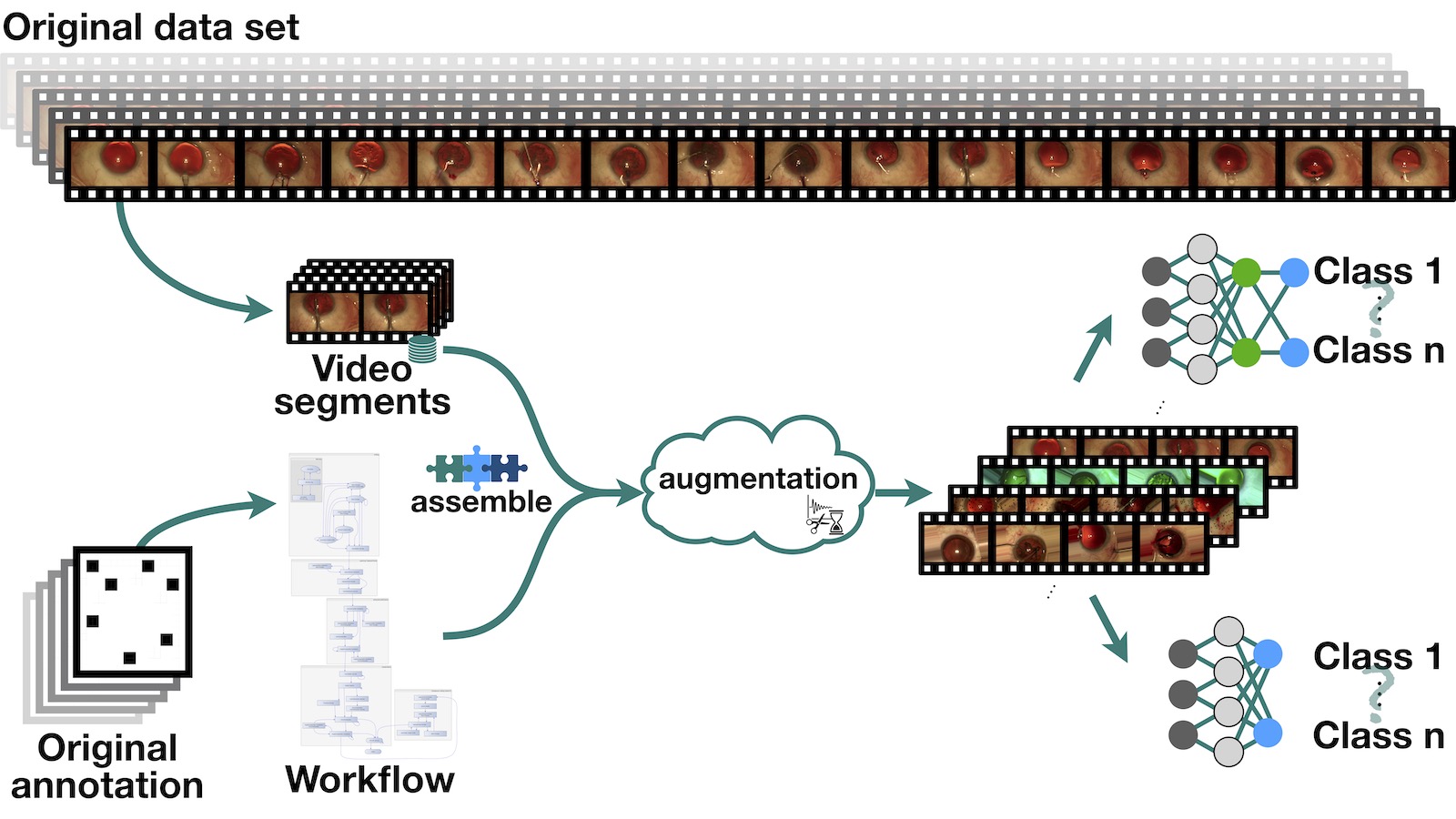
Neural networks have achieved remarkable result in event recognition in the field of medical image and video analysis in recent years. One of the main limitation for machine learning approaches is the lack of available annotated training data. This lack refers not only to the number of available datasets, but also to the number of variations of images and videos in existing datasets. Especially in the medical field, it is hard to extend the number of datasets. The reasons for this are various. For example, legal issues may prevent the publication of the data, or the occurrence of a disease is very rare, which makes it hard to record it. Moreover, medical data must be annotated by experts in an expensive and time-consuming process. Existing data augmentation methods are often applied to the image domain. These methods are not created sufficiently independent samples for video dataset.
Therefore, it is necessary to develop novel methods to extend the data set retrospectively or to generate synthetically new data set with annotations.
In my research I am working on the development of new methods, but also on the investigation of how to combine the existing method for the enhancement of video and image datasets to improve the recognition performance of e.g. neural networks.